| Home | Articles | Talks | Links | Contact Me | ISA | ThoughtWorks |
by David Rice
Prevent conflicts between concurrent business transactions by allowing only one business transaction to access data at once.
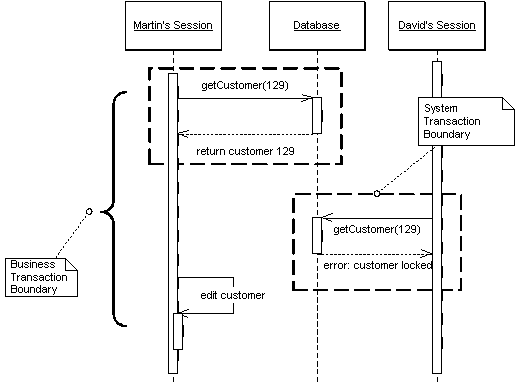
Offline concurrency involves manipulating data for a business transaction that spans multiple requests. The simplest approach to use is to have a system transaction open for the whole business transaction. Sadly this often does not work well because transaction systems are not geared to work with these long transactions. When you can't use long transactions you have to use multiple system transactions. At that point you're left to your own devices to manage concurrent access to your data.
The first approach to try is Optimistic Offline Lock. However Optimistic Offline Lock has its problems. If several people access the same data within a business transaction, then one of them will commit with no problems but the others will conflict and fail. Since the conflict is only detected at the end of the business transaction, the victims will do all the work of the transaction only to find the whole thing fails - wasting their time. If this happens a lot on lengthy business transactions the system can soon become very unpopular.
Pessimistic Offline Lock prevents conflicts by attempting to avoid them altogether. Pessimistic Offline Lock forces a business transaction to acquire a lock on a piece of data before it starts to use that data. This way most of the time, once you begin a business transaction you can be pretty sure you'll complete it without being bounced by concurrency control.
Implementing Pessimistic Offline Lock involves three phases: determining what type of locks you need, building a lock manager, and defining procedures for a business transaction to use locks. Additionally, if using Pessimistic Offline Lock as a complement to Optimistic Offline Lock it becomes necessary to determine which record types to lock.
Looking at lock types, the first option is to have an exclusive write lock. That is, require only that a business transaction acquire a lock in order to edit session data. This avoids conflict by not allowing two business transactions to simultaneously make changes to the same record. What this locking scheme ignores is the reading of data. If it is not critical that a view session have the absolute most recent data this strategy will suffice.
If it becomes critical that a business transaction always have the most recent data regardless of its intention to edit then use the exclusive read lock. Using an exclusive read lock requires that a business transaction acquire a lock to simply load the record. This strategy clearly has the potential of severely restricting the concurrency of your system. For most enterprise systems the exclusive write lock will afford much more concurrent record access than this strategy.
There is a third strategy combining more specialized forms of read and write locks that will provide the more restrictive locking of the exclusive read lock while also providing the increased concurrency of the exclusive write lock. This third strategy, the read/write lock, is a bit more complicated than the first two. The relationship of the read and write locks is the key to getting the best of both worlds:
Allowing multiple read locks is what increases the concurrency of the system. The downside of this scheme is that it's a bit nasty to implement and presents more of a challenge for domain experts to wrap their heads around when they are modeling the system.
In choosing the correct lock type you are looking to maximize system concurrency, meet business needs, and minimize code complexity. In addition, the locking strategy must be understood by the domain modelers and analysts. Locking is not just a technical problem as the wrong lock type, simply locking every record, or locking the wrong types of records can result an ineffective Pessimistic Offline Lock strategy. An ineffective Pessimistic Offline Lock strategy is one that doesn't prevent conflict at the onset of the business transaction or degrades the concurrency of your system such that your multi-user system seems more like single-user system. The wrong locking strategy cannot be saved by a proper technical implementation. In fact, it's not a bad idea to include Pessimistic Offline Lock in your domain model.
Once you have decided upon your lock type define your lock manager. The lock manager's job is to grant or deny any request by a business transaction to acquire or release a lock. For a lock manager to do its job it needs to know about what's being locked as well as the intended owner of the lock, the business transaction. It's quite possible that your concept of a business transaction isn't some thing that can be uniquely identified. This makes it a bit difficult to pass a business transaction to the lock manager. In this case take a look at your concept of a session as you are more likely to have a session object at your disposal. So long as business transactions execute serially within a session the session will serve as a fine Pessimistic Offline Lock owner. The terms session and business transaction are fairly interchangeable. The code example should shed some light on the idea of a session as lock owner.
The lock manager shouldn't consist of much more than a table that maps locks to owners. A simple lock manager might wrap an in-memory hash table. Another option is to use a database table to store your locks. You must have one and only one lock table, so if it's in memory be sure to use a singleton lock manager. If your application server is clustered an in-memory lock table will not work unless it is pinned to a single server instance. The database-based lock manager is probably more appropriate once you are in a clustered application server environment.
The lock, whether implemented as an object or as SQL against a database table, should remain private to the lock manager. Business transactions should interact only with the lock manager, never with a lock object.
It is now time to define the protocol by which a business transaction must use the lock manager. This protocol must include what to lock, when to lock, when to release a lock, and how to act when a lock cannot be acquired.
The answer to what depends upon when so let's look first at when. Generally, the business transaction should acquire a lock before loading the data. There is not much point in acquiring a lock without a guarantee that you will have the latest version of the item once it's locked. But, since we are acquiring locks within a system transaction there are circumstances where the order of the lock and load won't matter. Depending upon your lock type if you are using serializable or repeatable read transactions the order in which you load objects and acquire locks might not matter. Another option might be to perform an optimistic check on an item after you acquire the Pessimistic Offline Lock. The rule is that you should be very sure that you have the latest version of an object after you have locked it. This usually translates to acquiring the lock before loading the data.
So, what are we locking? While we are locking objects or records or just about anything, what we usually lock is the id, or primary key, that we use to find those objects. This allows us to obtain the lock before loading the object. Locking the object works fine so long as this doesn't force you to break the rule that an object must be current after you acquire its lock.
The simplest rule for releasing locks is to release them when the business transaction completes. Releasing a lock prior to completion of a business transaction might be allowable, dependent upon your lock type and your intention to use that object again within the transaction. Unless you have a very specific reason to release the lock, such as a particularly nasty system liveness issue, stick to releasing all locks upon completion of the business transaction.
The easiest course of action for a business transaction when it is unable to acquire a lock is to abort. The user should find this acceptable since using Pessimistic Offline Lock should result in failure happening rather early in the transaction. The developer and designer can certainly help the situation by not waiting until late in the transaction before acquiring a particularly contentious lock. If at all possible acquire all of your locks before the user begins work.
For any given item that you intend to lock access to the lock table must by serialized. With an in-memory lock table it's easiest to simply serialize access to the entire lock manager with whatever constructs your programming language provides. If you need concurrency greater than this affords be aware you are entering complex territory.
If the lock table is stored in a database the first rule is, of course, interact with the lock table within a system transaction. Take full advantage of the serialization capabilities that a database provides. With the exclusive read and exclusive write lock types serialization is simply a matter of having the database enforce a uniqueness constraint on the column storing the lockable item's id. Storing read/write locks in a database makes things a bit more difficult since read/write lock logic requires reads of the lock table in addition to inserts. Thus, it becomes imperative to avoid inconsistent reads. A system transaction with isolation level of serializable will provide ultimate safety as we are guaranteed not to have inconsistent reads. But using serializable transactions throughout our system might get us into performance trouble. Using a separate serializable system transaction for lock acquisition and a less strict isolation level for other work might ease the performance problem. Still another option is to investigate whether a stored procedure might help with lock management. Concurrency management can be tough so don't be afraid to defer to your database at key moments.
The serial nature of lock management screams performance bottleneck. A large consideration is lock granularity. The fewer locks required the less of a bottleneck you will have. A Coarse-Grained Lock can address lock table contention.
When using a system transaction pessimistic locking scheme, such as 'SELECT FOR UPDATE...' or entity EJBs, deadlock is a distinct possibility. Deadlock is a possibility because these locking mechanisms will wait until a lock becomes available. Suppose two users need resources A and B. If one gets the lock on A and the other on B both transactions might sit and wait forever for the other lock. Given that we're spanning multiple system transactions waiting for a lock does not make much sense. A business transaction might take 20 minutes. Nobody wants to wait for those locks. This is good. Coding for a wait involves timeouts and quickly gets complicated. So simply have your lock manager throw an exception as soon as a lock is unavailable. This removes the burden of coping with deadlock.
A final requirement is managing lock timeouts for lost sessions. If a client machine crashes in the middle of a transaction the lost business transaction is unable to complete and release any owned locks. This is an even bigger deal for a web application where sessions are regularly abandoned by users. Ideally you will have a mechanism managed by your application server rather than your application available for handling timeouts. Web application servers provide an HTTP session that can be utilized for timeout purposes. Timeouts can be implemented by registering a utility object that releases all locks for the session when the HTTP session becomes invalid. Another option would be to associate a timestamp with each lock and consider any lock older than a certain age invalid.
Pessimistic Offline Lock is appropriate when the chance of conflict between concurrent sessions is high. A user should never have to throw away work. Locking is also quite appropriate when the cost of a concurrency conflict is too high, regardless of the likelihood of that conflict. Locking every entity in a system will almost surely create tremendous data contention problems so remember that Pessimistic Offline Lock is very complementary to Optimistic Offline Lock and only use Pessimistic Offline Lock where it is truly required.
If you have to use Pessimistic Offline Lock you should also consider a long transaction. Although long transactions are never a good thing, in some situations they may work out to be no more damaging than Pessimistic Offline Lock, and they are much easier to program. Do some load testing before you choose.
Do not use these techniques if your business transactions fit within a single system transaction. Many system transaction pessimistic locking techniques ship with the application and database servers you are already using. Among these techniques are the 'SELECT FOR UPDATE' SQL statement for database locking and the entity EJB for application server locking. Why worry about timeouts, lock visibility and such when there is no need. Understanding these types of locking can certainly add a lot of value to your implementation of Pessimistic Offline Lock. But understand that the inverse is not true! What you have read here has not prepared you to write a database manager or transaction monitor. The offline locking techniques presented in this book are all dependent upon your system having a real transaction monitor.
 |  |